
Simple Decision Trees and Its Implementation
Published:
A decision tree is a machine learning model that makes decisions by recursively splitting data based on the best feature, forming a tree-like structure.
Why Use Decision Trees?
✅ Easy to understand – Works like a flowchart.
✅ Handles numerical & categorical data – No need for feature scaling.
✅ Feature importance – Identifies the most important factors.
✅ Widely used – In applications like fraud detection, medical diagnosis, and recommendation systems.
2. Understanding Gini Impurity
The Gini Impurity measures how “impure” a node is, meaning how mixed the classes are. It is used to determine the best split at each step.
Other options for impurity can be Entropy and MSE. In practice, the choice between Gini Impurity and Entropy often doesn’t significantly affect the performance of the decision tree.
Mathematical Formula:
For a dataset with C classes, Gini Impurity is calculated as:
\[Gini = 1 - \sum_{i=1}^{C} p_i^2\]Where:
- \( p_i \) is probability of an element belonging to class i.
- A Gini Impurity of 0 means the node is pure (all samples belong to one class).
3. Learn with Coding: Implementing Decision Tree from Scratch
import numpy as np
import matplotlib.pyplot as plt
from graphviz import Digraph
### **Step 1: Define beset split criteria**
def gini_impurity(labels):
"""
Compute Gini Impurity for a given set of labels.
return gini score: 0 means the node is pure (all samples belong to one class)
"""
unique, counts = np.unique(labels, return_counts=True)
probs = counts / counts.sum()
return 1 - np.sum(probs ** 2)
### **Step 2: Find the Best Split**
def best_split(X, y):
"""
Identify the best feature and min-threshold for splitting the dataset.
"""
best_feature, best_threshold, best_impurity = None, None, float('inf')
for feature in range(X.shape[1]):
thresholds = np.unique(X[:, feature])
for threshold in thresholds:
left = y[X[:, feature] <= threshold]
right = y[X[:, feature] > threshold]
impurity = (len(left) * gini_impurity(left) + len(right) * gini_impurity(right)) / len(y)
if impurity < best_impurity:
best_feature = feature
best_threshold = threshold
best_impurity = impurity
return best_feature, best_threshold
### **Step 3: Build the Decision Tree**
class DecisionTree:
"""
A simple decision tree classifier implementing recursive binary splits.
"""
def __init__(self, max_depth=6):
self.max_depth = max_depth
self.tree = None
def fit(self, X, y, depth=0):
"""
Train the decision tree model recursively.
"""
if depth == self.max_depth or len(set(y)) == 1:
return np.bincount(y).argmax()
feature, threshold = best_split(X, y)
left_idx = X[:, feature] <= threshold
right_idx = X[:, feature] > threshold
left_branch = self.fit(X[left_idx], y[left_idx], depth + 1)
right_branch = self.fit(X[right_idx], y[right_idx], depth + 1)
tree_structure = {f"Feature {feature}": {
"<= {:.2f}".format(threshold): left_branch,
"> {:.2f}".format(threshold): right_branch
}}
print(f"Splitting on Feature {feature} at threshold {threshold:.2f}")
return tree_structure
def plot_tree(self, tree=None, parent=None, graph=None):
"""
[Optional]Visualize the decision tree structure using Graphviz.
"""
if graph is None:
graph = Digraph()
tree = self.tree if tree is None else tree
if isinstance(tree, dict):
for key, value in tree.items():
node_id = f"node_{key}"
graph.node(node_id, key)
if parent:
graph.edge(parent, node_id)
self.plot_tree(value, node_id, graph)
else:
leaf_id = f"leaf_{tree}"
graph.node(leaf_id, f"Class {tree}", shape='box')
if parent:
graph.edge(parent, leaf_id)
return graph
Step 4: Train and Test the Decision Tree
# Example Dataset (X: Features, y: Labels)
X = np.array([[2, 3], [1, 1], [3, 4], [5, 6], [4, 5], [6, 2], [7, 3], [8, 5], [9, 7], [10, 8]])
y = np.array([0, 0, 1, 1, 1, 0, 0, 1, 1, 0])
tree = DecisionTree(max_depth=5)
tree.tree = tree.fit(X, y)
print(tree.tree)
# {'Feature 1': {'<= 3.00': 0, '> 3.00': {'Feature 0': {'<= 9.00': 1, '> 9.00': 0}}}}
tree_graph = tree.plot_tree()
tree_graph.view()
Output decision tree is showing as below:
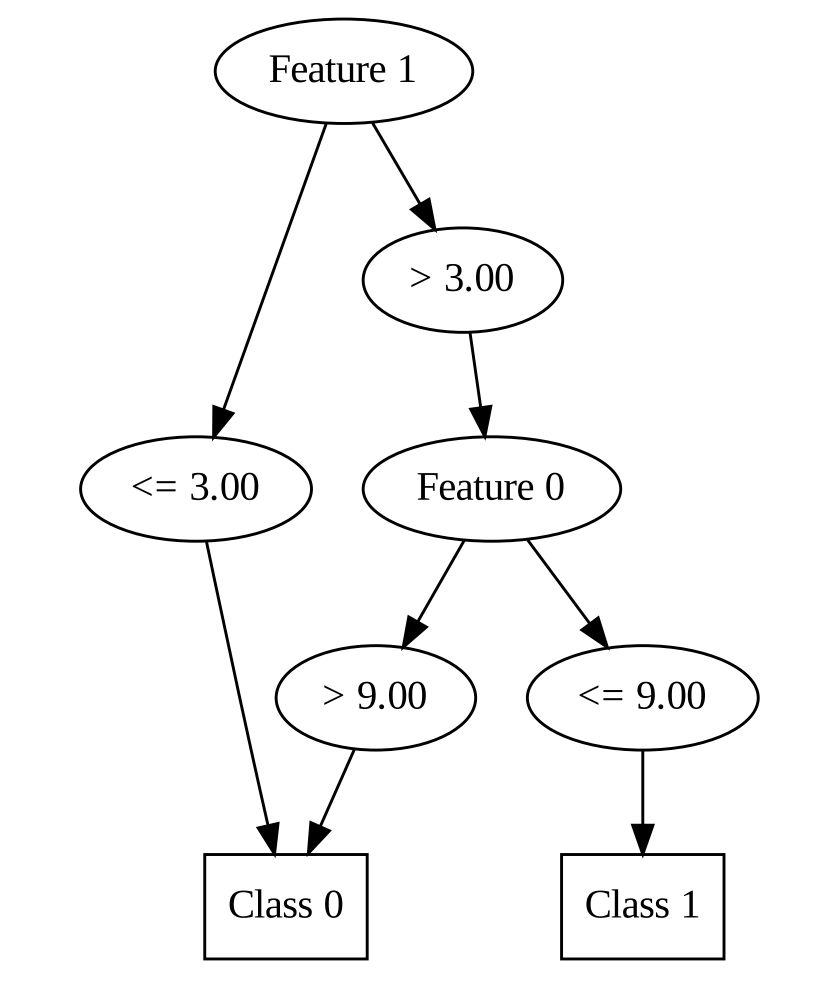
4. Key Takeaways
- Decision Trees recursively split data to make decisions.
- Gini Impurity helps determine the best feature to split on.
- Building from scratch strengthens understanding before using libraries like Scikit-Learn.
🤖 Disclaimer: This post is inspired by Educative.io AI learning course, and generated with AI-assisted but reviewed and refined by Dr. Rebecca Li, blending AI efficiency with human expertise for a balanced perspective.