
From Text Transformer to Vision Transformer Model
Published:
Transformer models have revolutionized large language models (LLMs) and are now widely used across multimodal AI applications, including text generation, conversational AI, and vision-based models. These models have set a new standard for natural language understanding, reasoning, and content generation by leveraging attention mechanisms to capture long-range dependencies and contextual relationships.
🎙️ If you prefer listening over reading, you can check out the AI-generated podcast version of this post.
1. Transformer Architecture for Text Generation
The Transformer model consists of several key components that enable efficient contextual understanding and text generation.
Text Tokenization and Encoding
- Process: Converts raw text into fixed-length vectors (embeddings) that are suitable for deep learning models.
- Purpose: Groups words with similar meanings closer in vector space, allowing the model to understand semantics beyond just individual words.
Example:
- The words “cat” and “car” may be similar in spelling but differ significantly in meaning. Their vector representations in an embedding space would be far apart.
- Conversely, “cat” and “dog” have similar attributes as animals, so their vector representations are closer together.
Extension: Text encoding is also crucial in search and recommendation systems, where pre-trained embeddings can enhance retrieval quality by identifying semantically similar content.
Positional Encoding
Transformers do not inherently understand word order, unlike traditional recurrent models. To preserve positional information, a sinusoidal function is used to encode positions:
\[PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)\] \[PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d}}}\right)\]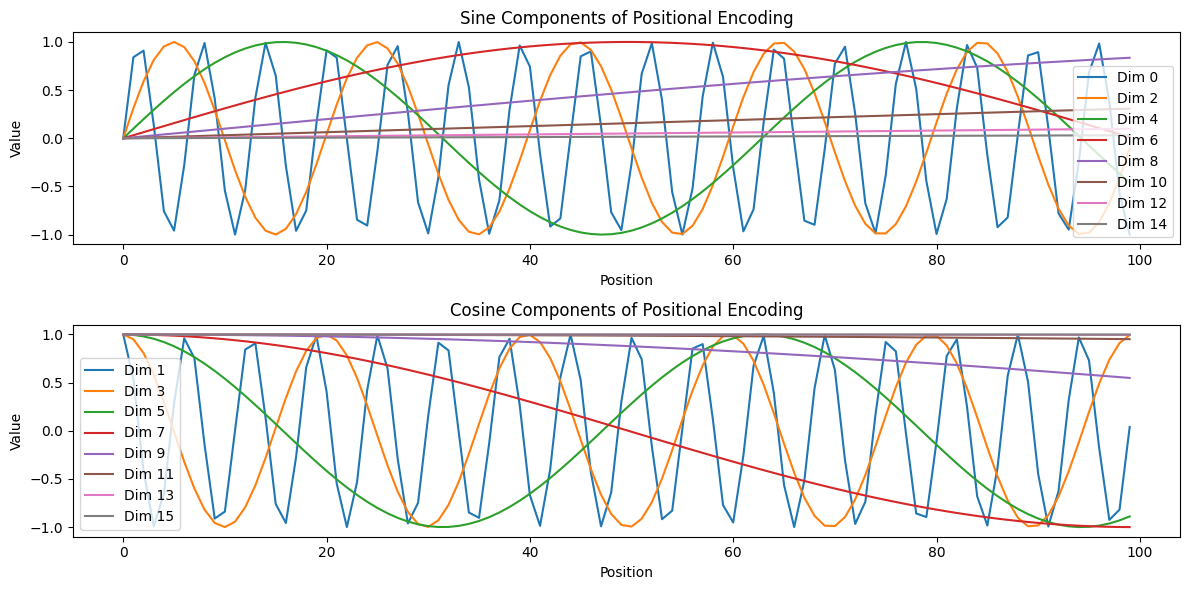
Example:
- The sentences “The cat lies on the sofa” and “The sofa lies on the cat” contain the same words but different meanings due to word order. Without positional encoding, the Transformer might treat them as identical, leading to incorrect understanding.
- Output: The final embedding consists of text embedding + positional encoding, allowing the model to recognize sequence information.
Takeaway: Positional encoding ensures that the Transformer maintains word order significance without relying on recurrence.
Encoder-Decoder Attension
Transformer model then use the attension mechanisum to caulate which part of the inputs are important when making prediction, the output is hte attention score of the input. To delve into the details of attention Mechanisum, please check my previous post.
| Feature | Transformer | BERT | GPT | LLaMA |
|---|---|---|---|---|
| Model Type | Encoder-Decoder | Encoder-only | Decoder-only | Decoder-only |
| Training Objective | Seq2Seq (Translation) | Masked Language Model (MLM) | Auto-Regressive (causal) | Auto-Regressive (causal) |
| Context Direction | Bi-directional | Bi-directional | Uni-directional (left-to-right) | Uni-directional (left-to-right) |
| Fine-Tuning Needs | Task-Specific | Pre-trained, requires fine-tuning | Pre-trained, requires fine-tuning | Pre-trained, efficient fine-tuning |
2. From Text Transformation to Vision Transformers
Vision Transformers (ViTs) adapt the Transformer architecture, originally designed for text processing, to computer vision tasks. Instead of using convolutional layers like CNNs, ViTs use self-attention mechanisms to process images, allowing them to capture long-range dependencies and contextual information across an image.
Image Patch Embedding
- Instead of tokenizing text, ViTs divide images into smaller patches.
- Each patch is flattened into a 1D vector and then embedded similarly to word embeddings in NLP.
Example:
- A 256×256 image can be divided into 16×16 patches.
- Each patch is independently converted into a fixed-length vector representation.
- These patches are then fed into a standard Transformer model.
Positional Encoding for Images
Since Transformers process input independently, they require positional encoding to maintain spatial relationships in images.
- ViTs use 2D positional encoding to assign spatial coordinates:
- This ensures the model understands which patches are adjacent and maintains the structure of objects in the image.
Attention in Vision Transformers
- Each image patch attends to all other patches to capture relationships between different parts of an image.
- This helps in recognizing global structures, unlike CNNs that rely on local receptive fields.
QKV Representation in Vision Transformers
In Vision Transformers, the attention mechanism is applied to the image patches using Query (Q), Key (K), and Value (V) matrices.
| Component | Definition in Vision Transformer |
|---|---|
| Query (Q) | Representation of the current image patch that needs to be compared with others. |
| Key (K) | Representation of all patches used to determine relevance to the query patch. |
| Value (V) | Contains the actual image patch features used to update the representation of the query. |
Example Use Cases:
- Object Detection: ViTs can detect objects without needing explicit feature maps.
- Medical Imaging: Captures contextual relationships across an entire scan.
- Image Classification: Achieves state-of-the-art accuracy on vision benchmarks.
Takeaway: Vision Transformers replace convolutional operations with self-attention, enabling more flexible and interpretable image representations.
Final Takeaways
- Transformers revolutionized both text and vision AI, providing superior context understanding and generalization.
- Self-attention ensures contextual consistency, while cross-attention integrates external knowledge.
- Vision Transformers adapt Transformer principles to images, leveraging patch embeddings instead of text tokens.
🤖 Disclaimer: This post is inspired by Educative.io AI learning course, and generated with AI-assisted but reviewed and refined by Dr. Rebecca Li, blending AI efficiency with human expertise for a balanced perspective.